One of the things that I like to do is create architecture diagrams of complicated systems.
We had Release Engineering and Release Operations in the Portland Mozilla office this week, providing a perfect opportunity to pick everyone’s brains about what the current state of our release infrastructure is like.
Behold: 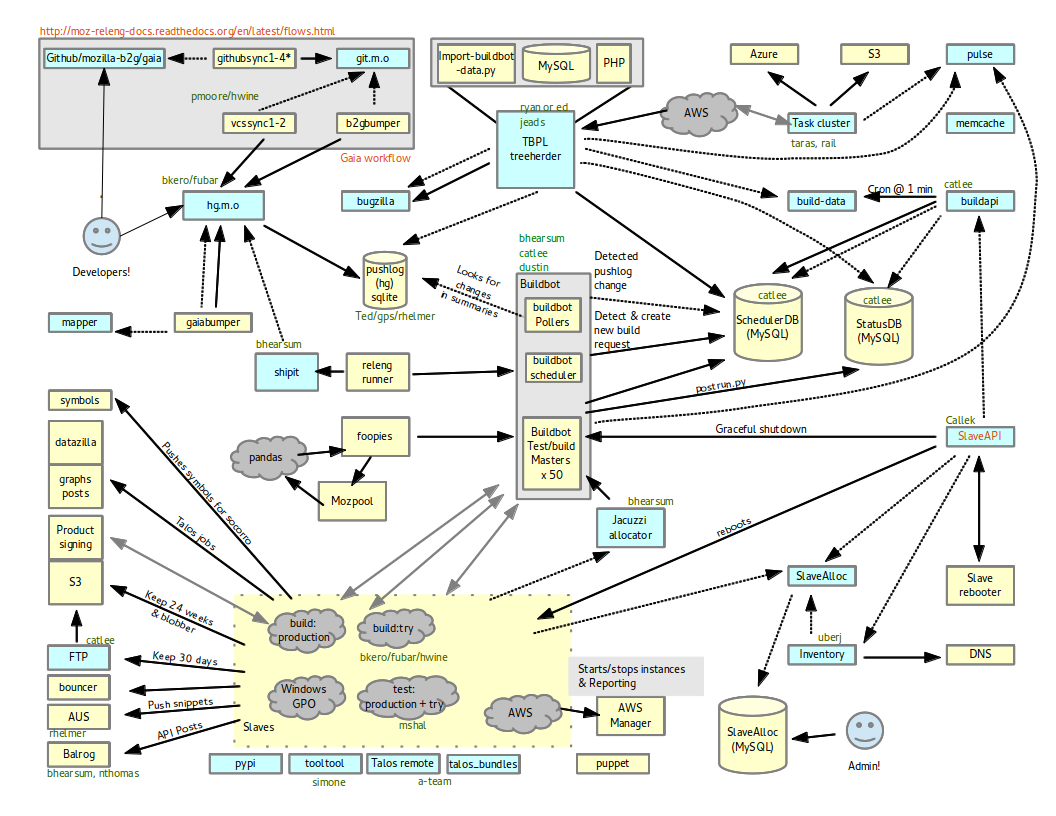
And here’s a version that includes some “tree closure reasons” in magenta:
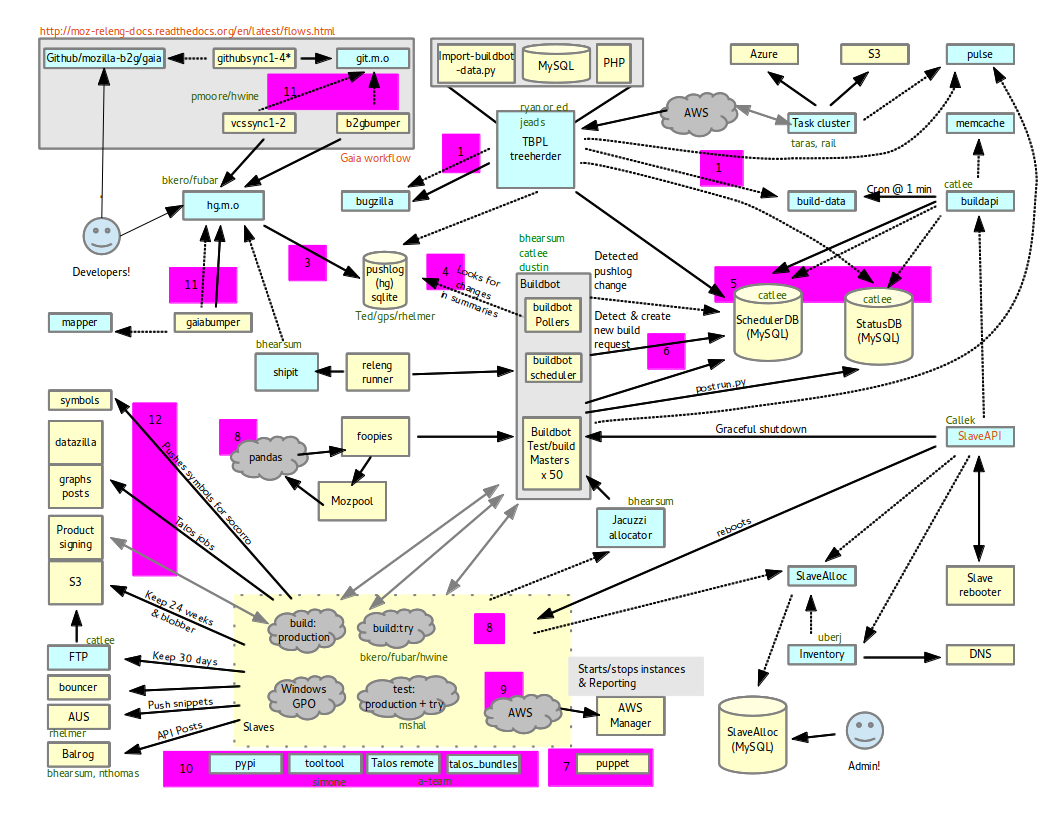
A tree closure is defined as an hg hook that prevents people from committing to a tree (like mozilla-central). It looks up status at treestatus.mozilla.org to figure out whether or not the tree is closed, and this value is updated manually by “sheriffs” who track tree status.
And the an initial key to the tree closure reasons (the numbers on the magenta blobs), is documented on the Mozilla wiki.
The goal of this document was to take brain dump information from everyone in the meeting, and create a relationship diagram of all the systems that everyone here supports. As you can see, it is pretty complex.
What I took away from creating this was:
- The cognitive load is very high for trying to diagnose the root cause for several kinds of tree closures.
- People loved being able to look at how each systems related to the others.
- No single person really had a model in their head of how everything represented in this diagram was related.
There’s a lot more work to do to link in documentation and create some related diagrams, which I’ll tackle next week. The kinds of questions I’d like to try to answer based on the information that I’ve gathered include:
- How does my patch get a build created for it?
- What single points of failure can we mitigate?
- What kinds of resilience do we need for our typical transient failures?
I really enjoyed identifying sources of tree closure and the kinds of failures that cause it. These are the kinds of problems I love working on solving — complicated, often unpredictable and largely driven by the normal work that people need to do to get their jobs done. There’s rarely a simple solution to things like experimental patches taking down large portions of a build infrastructure, and how we solve, or at least mitigate, these problems is fascinating.