Welcome to TaskCluster Platform’s 2015Q3 Retrospective! I’ve been managing this team this quarter and thought it would be nice to look back on what we’ve done. This report covers what we did for our quarterly goals. I’ve linked to “Publications” at the bottom of this page, and we have a TaskCluster Mozilla Wiki page that’s worth checking out.
High level accomplishments
- Dramatically improved stability of TaskCluster Platform for Sheriffs by fixing TreeHerder ingestion logic and regexes, adding better logging and fixing bugs in our taskcluster-vcs and mozilla-taskcluster components
- Created and Deployed CI builds on three major platforms:
- Added Linux64 (CentOS), Mac OS X cross-compiled builds as Tier2 CI builds
- Completed and documented a prototype Windows 2012 builds in AWS and task configuration
- Deployed auth.taskcluster.net, enabling better security, better support for self-service authorization and easier contributions from outside our team
- Added region biasing based on cost and availability of spot instances to our AWS provisioner
- Managed the workload of two interns, and significantly mentored a third
- Onboarded Selena as a new manager
- Held a workweek to focus attention on bringing our environment into production support of Release Engineering
Goals, Bugs and Collaborators
We laid out our Q3 goals in this etherpad. Our chosen themes this quarter were:
- Improve operational excellence — focus on sheriff concerns, data collection,
- Facilitate self-serve consumption — refactoring auth and supporting roles for scopes, and
- Exploit opportunities to differentiate from other platforms — support for interactive sessions, docker images as artifacts, github integration and more blogging/docs.
We had 139 Resolved FIXED bugs in TaskCluster product.

We also resolved 7 bugs in FirefoxOS, TreeHerder and RelEng products/components.
We received significant contributions from other teams: Morgan (mrrrgn) designed, created and deployed taskcluster-github; Ted deployed Mac OS X cross compiled builds; Dustin reworked the Linux TC builds to use CentOS, and resolved 11 bugs related to TaskCluster and Linux builds.
An additional 9 people contributed code to core TaskCluster, intree build scripts and and task definitions: aus, rwood, rail, mshal, gerard-majax, mihneadb@gmail.com, htsai, cmanchester, and echen.
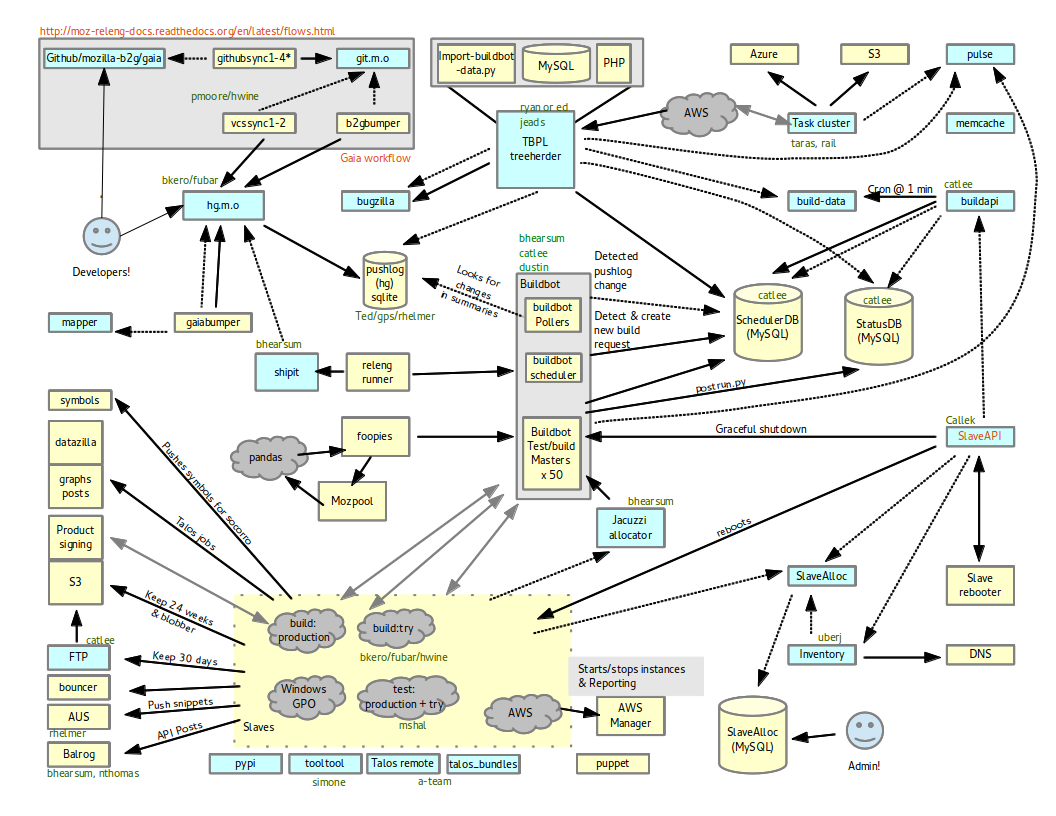
The Big Picture: TaskCluster integration into Platform Operations
Moving from B2G to Platform was a big shift. The team had already made a goal of enabling Firefox Release builds, but it wasn’t entirely clear how to accomplish that. We spent a lot of this quarter learning things from RelEng and prioritizing. The whole team spent the majority of our time supporting others use of TaskCluster through training and support, developing task configurations and resolving infrastructure problems. At the same time, we shipped docker-worker features, provisioner biasing and a new authorization system. One tricky infra issue that John and Jonas worked on early in the quarter was a strange AWS Provisioner failure that came down to an obscure missing dependency. We had a few git-related tree closures that Greg worked closely on and ultimately committed fixes to taskcluster-vcs to help resolve. Everyone spent a lot of time responding to bugs filed by the sheriffs and requests for help on IRC.
It’s hard to overstate how important the Sheriff relationship and TreeHerder work was. A couple teams had the impression that TaskCluster itself was unstable. Fixing this was a joint effort across TreeHerder, Sheriffs and TaskCluster teams.
When we finished, useful errors were finally being reported by tasks and starring became much more specific and actionable. We may have received a partial compliment on this from philor. The extent of artifact upload retries, for example, was made much clearer and we’ve prioritized fixing this in early Q4.
Both Greg and Jonas spent many weeks meeting with Ed and Cam, designing systems, fixing issues in TaskCluster components and contributing code back to TreeHerder. These meetings also led to Jonas and Cam collaborating more on API and data design, and this work is ongoing.
We had our own “intern” who was hired on as a contractor for the summer, Edgar Chen. He did some work with the docker-worker, implementing Interactive Sessions, and did analysis on our provisioner/worker efficiency. We made him give a short, sweet presentation on the interactive sessions. Edgar is now at CMU for his sophomore year and has referred at least one friend back to Mozilla to apply for an internship next summer.
Pete completed a Windows 2012 prototype build of Firefox that’s available from Try, with documentation and a completely automated process for creating AMIs. He hasn’t created a narrated video with dueling, British-English accented robot voices for this build yet.
We also invested a great deal of time in the RelEng interns. Jonas and Greg worked with Anhad on getting him productive with TaskCluster. When Anthony arrived, we also onboarded him. Jonas worked closely to get him working on a new project, hooks.taskcluster.net. To take these two bits of work from RelEng on, I pushed TaskCluster’s roadmap for generic-worker features back a quarter and Jonas pushed his stretch goal of getting the big graph scheduler into production to Q4.
We worked a great deal with other teams this quarter on taskcluster-github, supporting new Firefox and B2G builds, RRAs for the workers and generally telling Mozilla about TaskCluster.
Finally, we spent a significant amount of time interviewing, and then creating a more formal interview process that includes a coding challenge and structured-interview type questions. This is still in flux, but the first two portions are being used and refined currently. Jonas, Greg and Pete spent many hours interviewing candidates.
Berlin Work Week

Toward the end of the quarter, we held a workweek in Berlin to focus our next round of work on critical RelEng and Release-specific features as well as production monitoring planning. Dustin surprised us with delightful laser cut acrylic versions of the TaskCluster logo for the team! All team members reported that they benefited from being in one room to discuss key designs, get immediate code review, and demonstrate work in progress.
We came out of this with 20+ detailed documents from our conversations, greater alignment on the priorities for Platform Operations and a plan for trainings and tutorials to give at Orlando. Dustin followed this up with a series of ‘TC Topics’ Vidyo sessions targeted mostly at RelEng.
Our Q4 roadmap is focused on key RelEng features to support Release.
Publications
Our team published a few blog posts and videos this quarter: