[Update: David Wheeler provided the SQL that came out of this meeting.]

Last night, PDXPUG and Code-n-Splode got together to refactor the database for RT. David Wheeler, Jeff Davis and Mark Wong led the discussion.
Through the course of the meeting, the group chose to pick out a few key features that would be better served if the database schema was more normalized, and offered a few new constraints we thought would help manage the data. Toward the end of the meeting, Igal suggested having a Perl workshop to refactor the code related to one or more of the database changes. The idea here was to be helpful, rather than just poking holes in the schema.
David started the discussion off with an introduction to RT. RT was created about 10 years ago by Jesse Vincent of Best Practical, and the database schema has been augmented over the years to accommodate new functionality. They support both MySQL and PostgreSQL as backends, and tend to dislike using database-specific technology.
The killer feature in RT is its email-to-ticket functionality. Managing tickets directly from email is convenient and reduces the maintenance overhead for users and developers. RT has some great workflow controls – allowing specific actions to be taken when certain types of changes occur in a ticket.
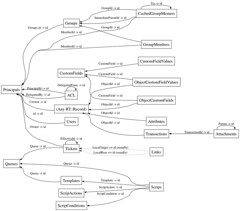
David reviewed a few key tables, and focused in on tickets, transactions and attachments. These tables are ones he was most familiar with from integrating RT in with I Want Sandy. A few key observations were:
- No foreign key constraints
- “Polymorphic relations” (tables storing multiple types of information)
- Default values in columns could be nicer
Addressing these three issues could fix potential data integrity problems, improve searchability and the make SQL queries of the data simpler and easier to maintain. We were also interested in improving the quality of the data stored in each row through constraints.
After this overview, we dove into a couple problems.
First, we weren’t sure in the database how to group workflow actions together. Based on the database, each transaction is independent, and “scrip” actions appear to be based on a row insert. The symptom of this is that if you create a workflow control, you can’t group together two “transactions” and yield a single email response. You’ll get an email for each transaction recorded in the database.
We didn’t dig into the associated Perl modules, but from a database perspective, a straight-forward normalization exercise solves the problem. We renamed transactions to ticket_events, and added a secondary table containing ticket_data. This new structure allows for multiple ticket_data rows to be linked to a single ticket_event. A simple view on these two tables could present nearly the same information as is available in transactions today, but now the system could group multiple ticket_data together. (UPDATE: I should have mentioned that the transactions table holds more than just ticket information. We would need at least one additional table to track changes in the rest of the database.)
We also tackled the schema representing email messages and their relationship with tickets. The existing database requires a JOIN between transactions and tickets to find. David and Jeff laid out a message table, split out interesting fields in email to make search and comparison easier. They also a foreign key to link email directly to both tickets and ticket_events.

Toward the end of the meeting, Mark wrote out the foreign key relationships for the new relational schema. We really needed a schema->diagram system so that we could view the schema in real-time. Some suggestions were made to use Autodoc with GraphViz to get real-time visualization of the entire schema. Next time!
The discussion also ranged into synthetic vs. natural keys, appropriate use and definition of NULLs, the difference between Entity relationship diagrams and relational schema diagrams, and the utility of workshops like this one to see how other people think about schema refactoring.
Before the meeting, David spent about an hour digging into the schema and talking with RT developers to get a feel for what types of changes they’d be open to. We’re not sure that the suggestions from our little workshop will be incorporated, mostly because the codebase for RT is large and complex. David’s plan was to send the suggestions on to Best Practical.
Remember… if your database has NULLs, the Terrorists have already won!
Null Quaeda is everywhere!
Hm. In RT, the ‘transactions’ table holds updates to records in multiple tables, not just to tickets.
(Though we do generally agree that having a second level of “things this transaction changed” would be a win.)
@Jesse: thanks for clarifying. We ended up focusing closely on the tickets because refactoring in a big group is actually hard.
Thanks for your virtual participation yesterday 🙂
got a suggestion via email to check out DbVisualizer – http://www.minq.se/products/dbvis
We didn’t dig into the associated Perl modules, but from a database perspective, a straight-forward normalization exercise solves the problem.
I thought that the Perl modules were the reason the database schema wasn’t better normalized. I’d be interested to see a followup to this post sometime, about whether or not any changes were made as a result of the discussion.
@Selena: DbVis is a great app for ERD’s, both from the database and object perspective.